OTP 23, PG2, and Outages
Table of Contents
Distributed systems is just a bunch of pigs coordinating. Image by DALL-E 2.
This is a description of a BEAM VM1 outage that occurred recently. I feel like there are not very many Erlang PMs out there, especially with Erlang clusters at scale, so hopefully, this postmortem serves as one of the few examples to learn from. We experienced a service degradation that could've amounted to an outage, but was solved with enough time to prevent an outage.
For context, we were running Erlang OTP 23.1 using an Elixir application with releases controlled by Distillery2, deployed on top of a Kubernetes cluster running on GCP. Our cluster was over 150 pods, with each pod containing a single elixir application instance running as PID 1.
At 7:23 PM UTC, when we received a massive traffic spike, the Kubernetes deployment began to autoscale and spin up new pods.
Symptoms began to appear at 7:43 PM UTC, where we noticed that new pods were being killed and restarted by the Kubernetes readiness probe. Our readiness probe was set to 30s, meaning that if a single instance was unable to start within 30s, it would be killed and restarted. This meant that no new pods were able to join the cluster.
The cause was a library called pg23, which effectively manages cluster membership. During the traffic spike, 7 pods began to fall behind in cluster message processing. As the cluster rapidly scaled, these 7 pods, which were already behind, began to lag even further. However, new pods joining the cluster would consume outdated cluster information from these 7 lagging pods, since pg2 maintains a strong ordering of messages. Consumption and processing of these messages required on average 6 minutes and occur before the process is ready to take requests, which far exceeded the readiness probe limit, causing Kubernetes to repeatedly stop and restart, further adding to the number of messages that needed to be processed by future pods.
This slow cascading failure caused pods to start dying until the root cause was narrowed down with observer_cli4, at which point we rolled the deployment and the issue was resolved.
In the future, the resolution will be to update to pg with OTP 24, which maintains a similar API without maintaining strong ordering.
1. Timeline of Events
- 7:43 PM UTC - Massive traffic spike.
- 7:43 PM UTC - New pods cannot start, and new pods are constantly killed by the Kube
readinessprobe. - 11:43 PM UTC - Managed to narrow down the issue to
pg2, determined that a temporary resolution was to kill high memory pods - 12:46 AM UTC - All 7 high memory pods were killed, and new pods were started
- 1:17 AM UTC - Completely rolled the deployment, issue resolved.
2. Symptoms and Root Cause
2.1. Erlang Configuration
pg23 is a process group management library used in the BEAM VM for cluster membership. Erlang clusters by default are full mesh, meaning that each node knows every other node. Of course, this inherently limits the number of nodes, as message scaling is \(o(n^2)\) within the cluster.
The Erlang and OTP in Action5 book mentions:
A cluster of Erlang nodes can consist of two or more nodes. As a practical limit, you may have a couple of dozen, but probably not hundreds of nodes. This is because the cluster is a fully connected network and the communication overhead for keeping machines in touch with each other increases quadratically with the number of nodes.
We are running a cluster with 150-200 Erlang nodes at any given time. In addition, our entire cluster runs on GCP preemptible instances, which means that nodes are liable to be killed at any time, generating far more intra-cluster bookkeeping messages. In other words, we're likely at the limit, if not over the limit of a full mesh network.
2.2. Kubernetes Configuration
For us, each Kubernetes pod corresponds to a single container, which in turn corresponds to a single Erlang node.
Our pods are configured with a readinessProbes of 30s and a period of 10 seconds. This means that the process within the pod has 30s to start, and every 10 seconds we check the status. If the status check fails more than once, we kill the pod and restart it at the beginning.
Pods are deployed using a Kubernetes deploymentSet, which automatically spins up more pods as traffic increases.
2.3. The Issue
Per the timeline above, the 7:42 PM traffic event triggered a cluster-wide scaleup. However, traffic already overloaded a few existing pods, which caused 7 pods to fall behind in traffic processing.
Because the BEAM VM implements TCP multiplexing, both connections to external clients and the rest of the cluster are handled on the same pipe, to conserve port usage. However, this means that, in rare cases, external traffic can cause resource starvation on cluster bookkeeping traffic, which is what I believe occurred here.
The 7:42 external traffic overloaded 7 specific pods. These pods, while processing external traffic, fell behind in processing cluster bookkeeping traffic, and therefore had a stale view of the cluster. In conjunction with the traffic, the massive scaleup Kubernetes initiated flooded the cluster with additional messages.
However, as new pods joined, the strong ordering property of pg2 meant that new pods needed to consume all messages from different nodes, including the stale messages from the 7 specific nodes. This processing exceeded the grace period given by Kubernetes, causing a repeated cycle of pods starting up, processing cluster messages, and being killed before they could finish.
Of course, as each pod was killed, Kubernetes attempted to restart the pod over and over. A cascading failure occurred: pods would start up, attempt to join, broadcast their membership, then be killed, adding more messages that needed to be processed by future pods. This means that each time Kubernetes attempted to restart a pod, the number of total messages that needed to be processed increased. A feedback loop of a slow start, getting killed by slow starts and making future starts even slower was established.
3. Diagnosis
Root cause analysis was established with two experiments:
- We took a pod that was repeatedly being rebooted and removed the probes and timed the startup
observer_cliwas used to determine what was taking up memory on high-memory pods.
The first experiment established that pods were not unable to join the cluster, but rather they were just very slow to join the cluster. This meant that there had to be something with cluster bookkeeping, at which point we began to suspect something either with GCP or our cluster management code.
The second experiment clearly established that pg2 was the culprit. observer_cli is a tool for the BEAM VM that is similar to htop, allowing you to determine what is consuming CPU and memory. Running observer_cli on a specific node revealed that the majority of the memory was being consumed by pg2, which we suspected to be cluster bookkeeping messages.
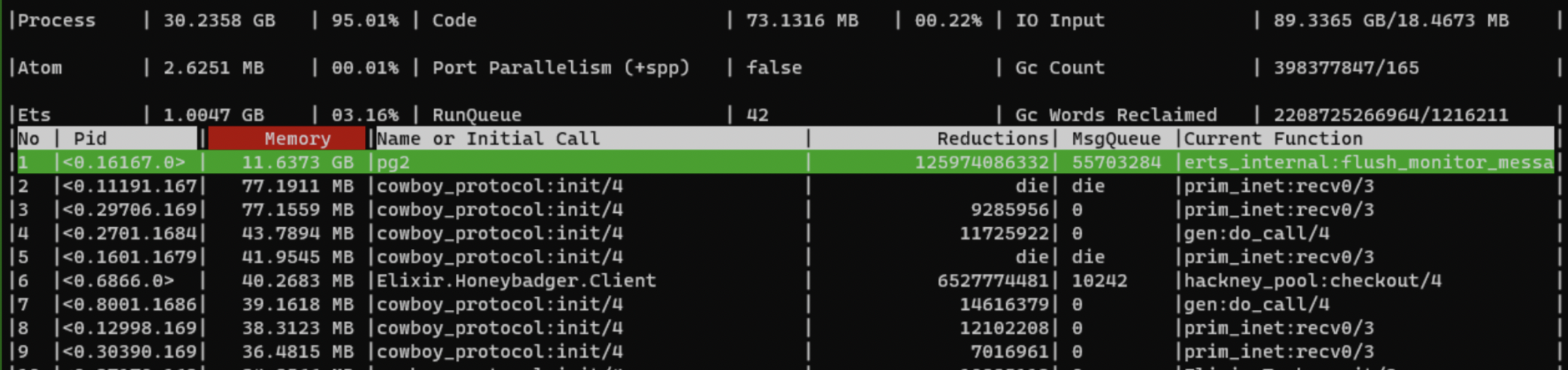
What
observer_clilooks like.
4. Resolution
It was determined that we should kill the seven high-memory pods to see if it would alleviate cluster traffic. After killing the pods, the effect was immediate: new pods began to spin up right away. After an hour, the decision was made to do a rolling deployment to create a completely new cluster state. New pods began to spin up without issue after the cluster state was cleared.
5. What I Learned
5.1. Distillery does not have easy logs for startup
We use distillery, which is a tool that handles generating startup code for deployments. However, distillery does not provide BEAM bootup logs, which greatly increased our debugging time.
5.2. gdb and strace don't work on the BEAM VM!
With no information about BEAM VM boot, I attempted strace and gdb the PID. The first hurdle was that we run services as PID 1, and newer Linux kernels prevent stracing on PID 1.
The second hurdle was that even when switching the PID, strace doesn't work as expected on the BEAM VM! strace on the BEAM VM PID will only show SELECT(0, NULL, NULL, NULL), which is a syscall used for subsecond waiting. I'm unsure what the root cause of this is, but I suspect this is because the BEAM VM uses greenlets and lightweight threads processing, which are invisible to strace on the root PID.
5.3. 150-170 nodes is likely the upper limit for full mesh Erlang.
The most important lesson is that 150-170 nodes are likely the upper limit. While we had easily scaled up to 120 nodes without problem, scaling from the Kubernetes autoscaler pushed us to a metastable failure6: a pathological state where once entered, the system is unable to recover by itself.
For others who are planning on attempting to scale Erlang clusters, these additional resources are useful: