Legible Complexity
Table of Contents
A few major outages in the past couple weeks have caused me to think about system reliability in a bit more detail. I've been rereading the notes from the snafucatchers repo, which lead me to Coping with Complexity, a paper by Jens Rasmussen and Morten Lind on how power plant operators deal with complexity and render massive systems legible to an operator.
I found this paper very interesting, especially in light of how it develops some models for system reliability that are pretty common these days. In particular, the paper focuses on defining the heuristics of operators when it comes to complex systems, and then develops a model of "top-down" evaluation, guided by computers. The paper also touches on the development of abstractions, a section I'm sure other software devs will enjoy.
1. Heuristics and Alerts
To quickly sum up the paper, Rasmussen and Lind propose two "simple"1 heuristics taken to handle issues:
- Thresholds - when a variable crosses an absolute threshold
- For software, this might be something like 100% CPU usage, or 95% RAM usage, or whatever parameter the cgroup is set to.
- Deviation from normal - when a variable deviates from historical data
- When an experienced operator knows what is normal and what is not. p95, p99, etc are all examples.
When I was working at Datadog, we translated there heuristics into alerts people could set up and saw many people using the thresholds alerts because they were simpler, but the deviation from normal is probably better for most use cases2. The main problem with the latter is that it requires operator experience: one must know what the system looks like under regular usage, and the regular deviations that occur. While Rasmussen and Lind do talk about this, I feel that they didn't emphasize it enough. Even if you have historical data about how the system performs, without knowledge of how the system reacts, this historical data is largely useless. Joey Lynch talked about this during the next generation cassandra conference in 2019, where he specifically stated how important his experience was in debugging problems.
Taking this one step further, it's clear that this poses some problems for transferring systems operations. For example, this could be handing off your service to a SRE team, or an ops team, or even just to another developer on your team who isn't as familiar with the service for oncall duty. Thresholds are easily transferable, they contain enough context by itself.
For example, imagine creating a threshold Grafana alert on "RAM usage >95%". This alert is filled with easily parsable context for other devs, it tells you:
- High RAM usage is not normal
- 95% is (possibly) some significant threshold (you may be able to infer that this is the threshold a memory limit for cgroups on this machine is setup, or when swap is triggered, or some other system configuration).
This alert is highly self contained, and is relatively easy to transfer over to another person. In fact, this alert doesn't even require you to know what the actual service on the machine is, but you can already infer some behaviors of the service.
However, imagine this alert is expanded into a deviation from normal alert, such as "RAM usage >95% for 5 min". This introduces some operator specific context:
- 5 min means that this system may actually see brief bursts of high memory usage, but those aren't significant unless it's sustained.
- One can then infer that this system probably normally hits high memory usage.
This now introduces a pretty big spot for problems: second guessing the alert. Is high ram usage for 4 minutes and 30 seconds significant? Is 3 minutes of sustained high ram usage significant? By making changing this alert from threshold to deviation, it introduces pretty significant contextual problems.
Overall, this implies that systems that need to be operated by people who aren't as familiar with the code should lean towards threshold alerts instead of deviation ones.
2. Attention, Aggregation, Abstraction
Rasmussen and Lind have a very nice picture I'll reproduce here:
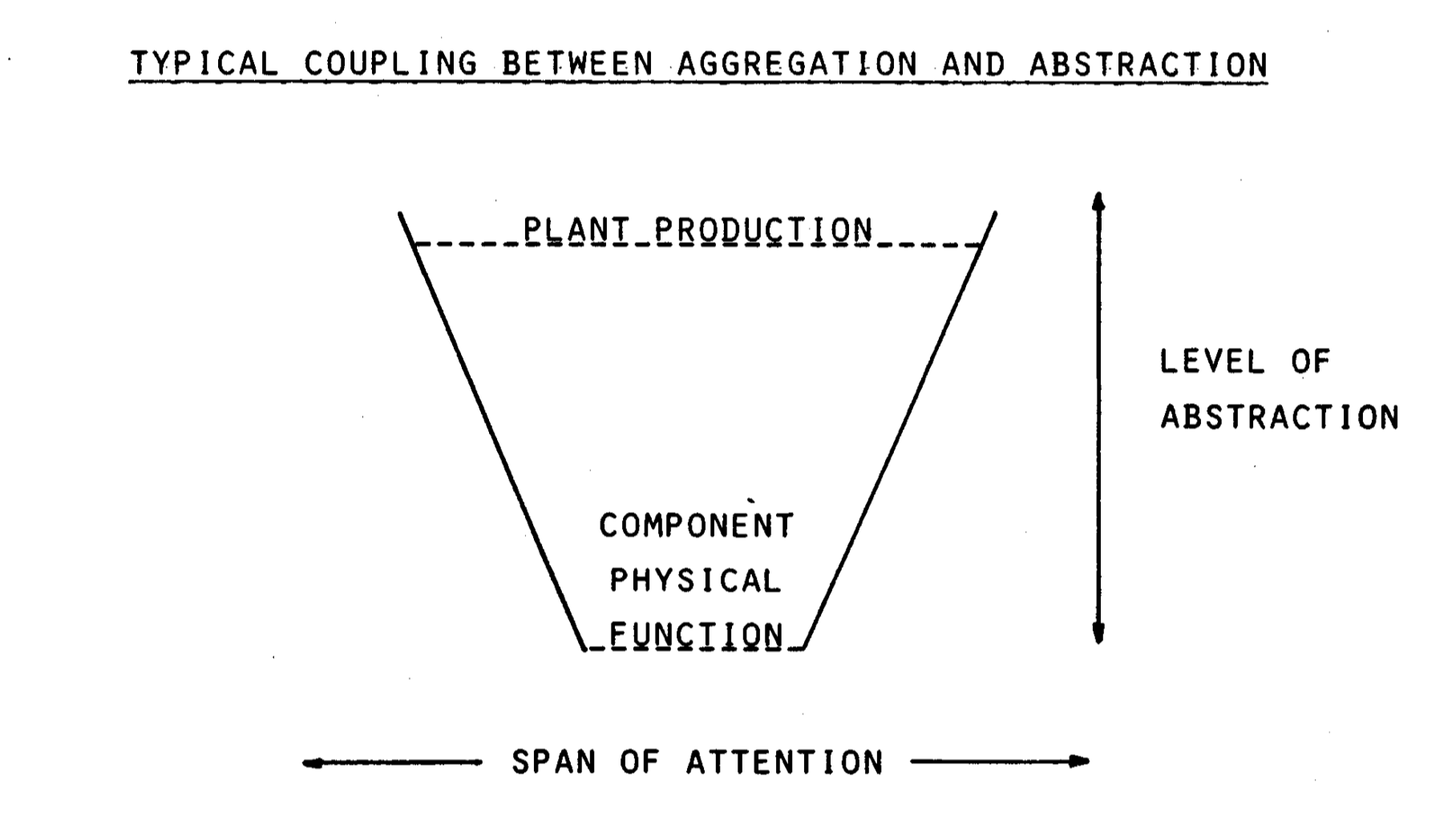
Translated into software terms, this means that the higher abstractions an operator has to manage, the more removed it is from physical function. This has implications for attention: abstractions allow an operator to focus on more components.
This is pretty self explanatory on its face, but it actually helps us design more useful dashboards. We've all seen massive Grafana dashboards that contain pretty much every metric known to man, which renders the dashboard useless. Taking Rasmussen and Lind's idea, dashboards should:
- limit themselves to high level metrics if they track multiple components
- have more granular metrics the fewer things they cover
This is to say, if you have a platform with multiple services, don't create a dashboard that has very granular metrics for every service. This won't help the operators (and you) quickly figure out which components are having problems at a glance, and only serve to confuse. The opposite should happen for dashboards about a single component, presumably when you're looking at a dashboard dedicated to a single component, you've already isolated a problem with this service. This means that dashboards dedicated to a single component should have very granular debugging metrics, such as JMX/Java Flight Record metrics for JVM services, garbage collection logs, etc.
3. Computer Guided Debugging/Ops
The last portion of the paper is dedicated to talking about how computers can aid operators through this layer of complexity. Specifically they state:
Considering only this more restricted "system" in a specific situation, generally only three levels of abstraction are relevant to the operator, viz. the process or function under consideration (the "what" level); the purpose of this process for the next higher level (the "why" level); and, finally, the level below representing the more physical properties (the "how" level, i.e. the implementation level).
- from pg. 21
This goes beyond just recognizing the differing abstraction layers within your system, Rasmussen and Lind point out how important it is to actually relate these abstractions to each other. Each abstraction builds upon one another, and an operator should flow seamlessly between these abstraction layers. This can take the effect of sharing a singular time range for debugging (something Grafana provides for you when you navigate to different dashboards) to linking specific metrics together, such as load balancer queues vs service response time. Keeping in mind how each of your metrics and alerts relate to one another is just as important as having them in place.
Another crucial portion of making complexity legible is the understanding of how abstractions are built. Rasmussen and Lind point this out:
the task will be formulated from an identification of the discrepancy between the "top-down" proper function and the "bottom-up" actual function.
- from pg 17
This is saying that your direct effects will be from the top down, but you've built abstractions from the bottom up. In other words, you're likely to be alerted from an outage by your customers or clients, which will be at the top most layer of the abstraction hierarchy, but your problem will be with a single component or components. Every operator must then go through a process of translating a coarse piece of information (i.e. "your service isn't responding to API requests") to a more granular one ("API requests to client X have 90% failure rate") to a service level information ("service 1 has crashed, kubernetes didn't start a new pod") to a resolution ("kick the pod, and start a new one"). This means that the abstractions you've built for the service actually run counter to how people use it! Keeping this in mind is important for debugging an outage.
Every software dev must wrangle complexity, from abstractions in their code to abstractions in their system. Recent adoption of cloud software, cloud monitoring software, cloud "agnostic" software have all served to create ever more abstractions between a programmer and their code, and untangling this mess of abstractions will help make better, more reliable systems.